There are several forms for modern parallelism. Two commonly-used are:
- Tensor Parallelism distributes the weights within a layer between GPUs.
- Intra-layer parallelism distributes full layers between GPUs.
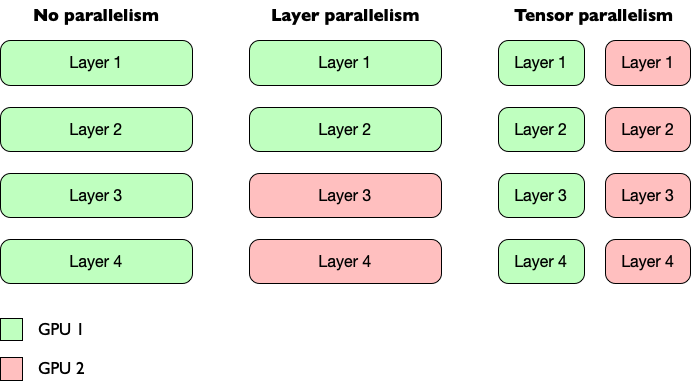
Model parallelism makes it possible to use models that would be too large for a single GPU’s VRAM by using the VRAM of multiple GPUs.
Model parallelism can also speed up models by performing work in parallel. This is clearly the case for tensor parallelism, but the same can be achieved for layer parallelism through pipelining.