Scaled dot-product attention
Head mapping variants
Standard multi-head scaled-dot-product attention uses the same number of query, key, and value heads. The -th head of the queries always interacts with the -th head of the keys to calculate an attention matrix and that attention matrix is used with the -th head of the values to compute new representations.
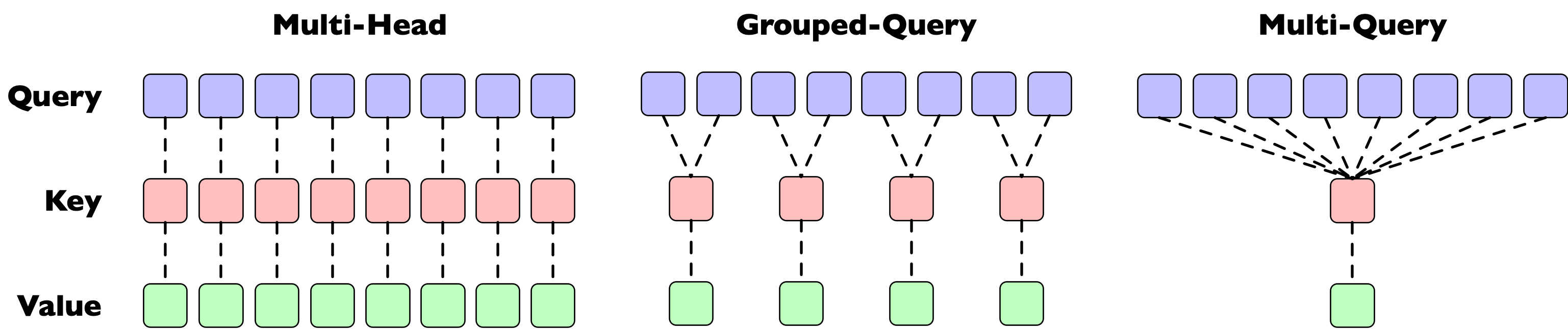
Multi-Query Attention
There have been two commonly-used approaches to move away from a 1:1:1 mapping. Multi-Query Attention (Shazeer 2019) uses just a single key and a single value head. When computing in attention, the query is broadcast. Example snippet that simulates the shapes:
import torch
# [batch_size=20, heads=12, seq_len=20, head_size=32]
query = torch.rand([16, 12, 20, 32], dtype=torch.float32)
# [batch_size=20, heads=1, seq_len=20, head_size=32]
key = torch.rand([16, 1, 20, 32], dtype=torch.float32)
# [batch_size=20, heads=12, seq_len=20, seq_len=20]
attention_unnorm = torch.matmul(query, key.transpose(-1,-2))The value is broadcast in a similar manner as well. The main motivation for reducing the number of key/value heads is that decoding is memory bandwidth-bound. Using a single key/value head cuts down data transfer.
Grouped-Query Attention
Grouped-Query Attention (Joshua Ainslie et al., 2023) is a similar optimization, but rather than using a single head, but uses a 1:m mapping from key/value heads to query heads. For instance, if a model uses 8 query heads and 4 key-value heads, each key-value head maps/broadcasts to 2 query heads. This is a compromise between the memory bandwidth optimization of Multi-Query Attention and the more powerful Multi-Head Attention.
Logit transformations
Softcapping
Some models (e.g. Gemma2 and Grok) use soft-capping of attention logits. See Logit soft-capping.